Innovating Open-Source AI: Orca's Challenge to ChatGPT
Written on
Chapter 1: The Rise of Community-Driven AI
The concept of community-driven AI chatbots that rival or even surpass proprietary models like ChatGPT is undeniably appealing. It evokes a sense of empowerment, as ordinary individuals take on the tech titans of Silicon Valley. Nevertheless, platforms such as Chatbot Arena consistently show that models backed by billions of dollars continue to dominate the field.
In a surprising move, Microsoft has introduced Orca, a compact open-source model that utilizes a novel training approach. Despite being significantly smaller—potentially hundreds of times less than models like GPT-4—Orca boldly asserts its competitiveness, claiming, “We belong in this arena.”
Remarkably, Orca sometimes outperforms larger models and decisively surpasses what was previously considered the top open-source contender, Vicuna. What exactly sets Orca apart from the rest?
For those eager to stay informed about the rapidly evolving AI landscape while feeling empowered to take action, my free weekly AI newsletter is a must-read.
A Shift in Training Paradigms
In the realm of AI development, financial resources play a crucial role, particularly for models with billions of parameters. The costs associated with:
- Acquiring sufficient data can run into the millions.
- Training the foundational model can also be in the millions.
- Fine-tuning the model may require hundreds of thousands.
The challenges are particularly daunting when it comes to Reinforcement Learning from Human Feedback (RLHF), which is often out of reach for anyone without substantial quarterly revenues. As a result, only a select few companies can afford to engage in the "let's build massive models" competition.
This reality has prompted researchers to adopt a more strategic approach, focusing on efficient training methods rather than sheer scale. In the context of Generative AI, this means embracing the technique known as distillation.
Understanding Distillation
In essence, distillation is a method where a smaller model is trained to mimic the responses of a larger, more established one. This approach is grounded in the understanding that large models are often over-parameterized.
To simplify, among the billions of parameters in models like ChatGPT, only a select few are truly essential. This leads to two key insights:
- Large models are necessary to grasp complex representations of our world.
- Most parameters in these models tend to remain unused.
Given this, researchers pondered whether a smaller model could emulate certain features of a large model through imitation, thereby eliminating the need for extensive learning.
The Distillation Process
As you might expect, the distillation process involves using a larger model to train a smaller one. The typical sequence in open-source AI development is as follows:
- A Large Language Model (the 'teacher') generates a dataset of {user instruction, response} pairs, often using ChatGPT as a reference.
- A smaller model (the 'student') is selected, usually comprising 5 to 15 billion parameters.
- The student model learns to minimize the differences between its outputs and those of the teacher.
This method allows the smaller model to adopt the teacher's style and achieve comparable results at a fraction of the cost.
While this sounds promising, it does come with caveats. These smaller models often struggle with reasoning abilities, leading to significant underperformance in complex tasks.
Chapter 2: Breaking New Ground with Orca
Orca's researchers recognized that many open-source models tend to exaggerate their capabilities. For instance, while Vicuna claims to achieve around 89% of GPT-4's performance in terms of style and coherence, this figure drops dramatically—by nearly 5400%—when assessing complex reasoning tasks.
In fact, GPT-4 outperformed Vicuna by a staggering 55 times in certain logical deduction scenarios.
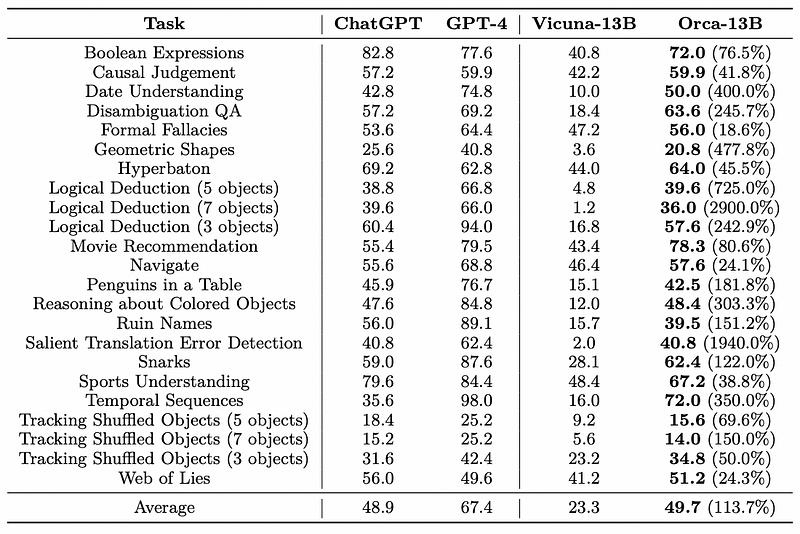
Moreover, in some assessments, Orca has even surpassed GPT-4, demonstrating a 3% improvement over a model that could be 100 times its size.

With an average performance that exceeds ChatGPT-3.5 while doubling Vicuna's results, Orca marks a significant achievement for open-source models, although it still trails behind GPT-4 in most evaluations.
Key Innovations of Orca
So, how does Orca manage to outshine other open-source models while occasionally matching or even exceeding its larger counterparts?
#### Explanatory Teaching Approach
Unlike previous models, Orca's training included an additional layer of complexity. Instead of relying solely on basic {user instruction, answer} pairs, the researchers incorporated a set of system instructions aimed at emulating the teacher's reasoning process.
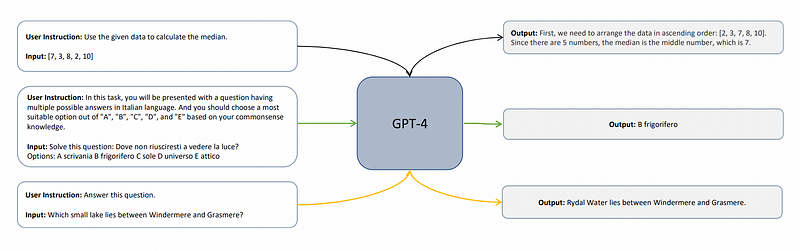
This approach compels the student not only to imitate the output quality of GPT-4 but also to adopt its cognitive strategies.
#### Progressive Learning Strategy
In a departure from standard practices, Orca utilized two teachers in its training: ChatGPT as an intermediate instructor for simpler tasks, followed by GPT-4 for more complex ones. This mirrors human learning, where foundational skills are developed before tackling advanced concepts.
The results of this progressive learning method were markedly superior compared to training with just GPT-4.
Looking Ahead: What Lies Beyond Orca?
Orca's remarkable success, achieved through seemingly minor adjustments, highlights the limited understanding we currently have of AI.
It's intriguing that Microsoft, a company deeply invested in the success of ChatGPT, is the one leading this innovative effort in open-source AI. This suggests that Microsoft and OpenAI may be re-evaluating their strategies for developing future models like GPT-5.
While it's likely that such models will still be expansive, there's increasing pressure for efficiency in AI technology. The rapid advancements in AI research are exhilarating, hinting at a promising future for this field.
As Orca paves the way for a new era in open-source AI, the implications for Silicon Valley and beyond could be profound.
For more insights into AI developments, feel free to join my newsletter!