Strategic Defenses for Adversarial Machine Learning
Written on
Chapter 1: Introduction to Adversarial Machine Learning
The increasing integration of machine learning (ML) models into vital business functions has led to a corresponding rise in attempts by malicious entities to compromise these systems for their own gain. Consequently, establishing effective defense mechanisms is crucial, especially in high-stakes areas such as autonomous vehicles and financial systems. This article will examine prevalent attack methods and explore the latest defensive strategies to safeguard machine learning systems against adversarial threats. Let’s delve into the fundamentals of protecting your AI investments.
Chapter 2: Understanding Adversarial Attacks
"Know your adversary" — a phrase attributed to Sun Tzu’s The Art of War — is just as relevant to contemporary machine learning as it was in ancient military strategy. Before we outline defense strategies against adversarial attacks, it is essential to understand how these attacks operate and the various forms they can take, along with some successful attack examples.
Goals of Adversarial Machine Learning Attacks
Generally, adversaries target AI systems for one of two primary purposes: to manipulate the model's predictions or to extract and exploit the model and its training data.
#### Attacks to Influence Model Outputs
Attackers may introduce misleading data or noise into a model's training set or inference input to skew its outputs. This might involve attempting to evade a machine learning-based security filter, such as fooling a spam detector to allow unwanted emails into your inbox. Alternatively, attackers might aim for outcomes that benefit them, such as seeking an inflated credit score from a banking model. Additionally, some attackers may intend to render a model ineffective, for instance, by targeting a facial recognition system to misidentify individuals or completely fail to recognize them, thereby crippling security protocols at critical locations.
#### Attacks to Steal Models and Data
Another motive for attackers is to capture the model itself or its training data. By persistently probing the model with different inputs, they can learn to replicate its behavior, either for personal use or resale. They may also extract sensitive training data, such as personally identifiable information or medical records, which hold significant value in the illicit data market.
Types of Adversarial Attacks
Adversarial machine learning can be divided into two categories. In white-box attacks, the adversary has complete access to the model's architecture and weights, allowing them to feed any input and observe internal operations. In contrast, black-box attacks provide no insight into the inner workings of the target system; attackers can only submit input samples and analyze the resulting outputs.
Unsurprisingly, white-box attacks are typically more effective due to the detailed information available to the attackers. Regardless of their access level, adversarial attacks can be classified further into:
- Evasion attacks
- Data-poisoning attacks
- Byzantine attacks
- Model-extraction attacks
#### Evasion Attacks
Evasion attacks aim to modify a model's outputs, tricking it into making incorrect predictions by subtly altering input data during inference. A notable example involves an image of a panda that, when noise imperceptible to humans is added, is misclassified as a gibbon.

Attackers often use techniques like the Fast Gradient Sign Method (FGSM) to create this noise, which maximizes the prediction error. FGSM is effective only in white-box scenarios, while black-box attackers must employ techniques like Zeroth-Order Optimization.
Video: Practical Defenses Against Adversarial Machine Learning
In this video, experts discuss various practical defenses against adversarial machine learning, offering insights into effective strategies.
#### Data-Poisoning Attacks
Data-poisoning attacks seek to taint a model’s training set, impacting its predictions. Attackers may need direct access to the training data, which could come from insider threats, such as employees involved in developing the ML system.
Consider a dataset used to train a credit-scoring model. If every 30-year-old in the dataset is assigned a high credit score, this backdoor could be exploited by corrupt employees, leading to unjust approval of credit lines.
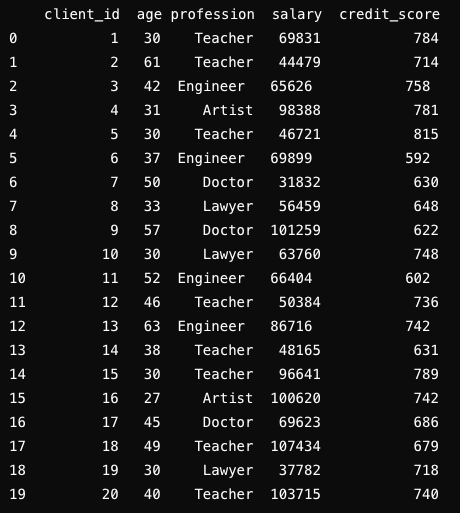
Yet, data poisoning can also occur without direct access. As much training data is user-generated, anyone can introduce malicious samples into training datasets.
Video: Defending Against Adversarial Model Attacks
This video explores various strategies to defend against adversarial model attacks, providing practical insights for practitioners.
Chapter 3: Defense Strategies for Adversarial Machine Learning
With an understanding of the adversary's tactics, let’s explore several strategies to bolster the resilience of AI systems against attacks.
#### Adversarial Learning
Adversarial learning, or adversarial training, is a straightforward method to enhance a machine learning model's robustness against evasion attacks. The concept involves generating adversarial examples and incorporating them into the training dataset, enabling the model to learn to make accurate predictions for these perturbed inputs.
During training, a separate batch of adversarial examples is generated based on the model's current weights. The loss function is then evaluated separately for both the original and adversarial samples, with the final loss being a weighted average.
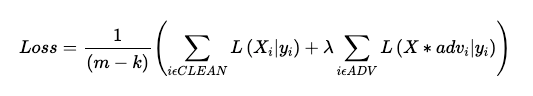
While effective, adversarial learning has limitations; models trained this way are only robust against the specific attack types used during training.
#### Monitoring
Another defense strategy focuses on monitoring requests sent to the model to identify adversarial samples. Specialized models can be employed to detect intentionally altered inputs, allowing for early identification and response to potential attacks.
By flagging manipulated inputs, monitoring systems can trigger alerts and initiate proactive measures to mitigate risks. For instance, in autonomous vehicles, monitoring could identify altered sensor data, prompting a switch to safe mode.
#### Defensive Distillation
Research from Penn State University and the University of Wisconsin-Madison suggests using knowledge distillation as a defense against adversarial attacks. This involves transferring the knowledge encoded in the output probabilities of a larger model to a smaller one, maintaining similar accuracy while enhancing robustness.
The process begins with training the initial model on a dataset, yielding probabilistic outputs that provide richer information than traditional labels. A new training set is created using these probabilities, and a second model is trained on this dataset.
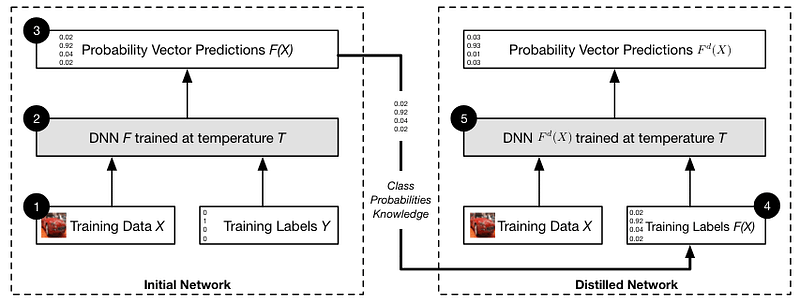
This approach allows the distilled model to generalize better and resist adversarial perturbations.
#### Defense Against Data-Poisoning Attacks
To guard against data-poisoning attacks, it is crucial to control access to the training data and verify its integrity. Key principles include:
- Access Control: Enforcing policies that restrict data modifications to authorized users.
- Audit Trails: Maintaining records to track user actions and quickly identify malicious behavior.
- Data Sanitization: Cleaning training data to remove potential poison samples.
#### Differential Privacy
Differential privacy is a technique designed to safeguard individual data privacy while enabling aggregate analysis. It involves adding controlled random noise to query results, thereby obscuring sensitive information while allowing for accurate analysis.
In training machine learning models, this technique ensures that the addition or removal of a single data point does not significantly affect the model's output, preserving the privacy of individual entries.
#### Defense Against Model-Extraction Attacks
To counter model-extraction attacks, limiting the frequency of API queries can slow down the extraction process. However, determined adversaries may find ways to circumvent these limits.
Another tactic is to introduce noise into the model’s outputs, striking a balance between usability and security. Additionally, watermarking outputs can help track and identify stolen models, providing a legal recourse against misuse.
Chapter 4: Evaluating Defense Strategies
Choosing defense strategies against adversarial machine learning attacks involves multiple considerations. Typically, the process begins with assessing the types of attacks to protect against and analyzing available methods based on their effectiveness, impact on performance, and adaptability to new attack techniques.
Conclusion
The field of adversarial machine learning is rapidly evolving. As attackers innovate, defenders must also adapt. The ongoing research focuses on balancing defense effectiveness with complexity and evaluating new strategies against standardized benchmarks.
In summary, the landscape of adversarial machine learning is characterized by a continuous interplay between attack and defense strategies, impacting the security and trustworthiness of AI systems across critical applications.

Thank you for reading! If you found this article helpful, consider subscribing for updates on future posts. For consulting inquiries, feel free to reach out or book a session for personalized guidance.