Streamlining Data Management with DynamoDB's Single-Table Approach
Written on
Chapter 1: Understanding Single-Table Design
DynamoDB's single-table design is a highly effective method for organizing and managing data with efficiency. In this article, we will delve into how this strategy can simplify your database structure, enhance query performance, and lower expenses.
What is Single-Table Design?
In the context of DynamoDB, we utilize a single table to store all types of data instead of creating multiple tables. Each entry in this table corresponds to a unique entity, using a combination of partition and sort keys for data organization and retrieval.
Benefits of Single-Table Design
- Simplicity: Handling a single table is far easier than managing multiple tables with intricate relationships.
- Performance: By denormalizing data and tailoring it for specific access patterns, we can execute queries quickly with minimal latency.
- Cost-Effectiveness: With DynamoDB's pay-per-request pricing, we incur costs only for the resources used, making it economical to scale our applications.
How Does It Function?
Let's examine a straightforward e-commerce example featuring products, orders, and customers, including both Admin and Customer users with the following requirements:
- Admin Operations: Ability to Create, Read, Update, and Delete (CRUD) products.
- Customer Operations:
- Place orders for products.
- Review order history.
- Access details of each order, including the associated products.
- Admin Reporting:
- Identify which products are purchased in each order and by which customers.
- Understand all products linked to specific orders.
To visualize these relationships, we have many products associated with many customers, all interconnected through orders.
Entity Relationship Diagram
To meet these needs, we will implement DynamoDB's single-table design. The primary key (PK) will differentiate between products and orders, while the sort key (SK) will sort within each type of entity. We will also employ global secondary indexes (GSI) to facilitate efficient queries based on customer IDs, product IDs, and order IDs. This schema enables us to effectively manage product and order data, streamline customer interactions, and provide valuable insights for admins.
Proposed Schema
- Primary Key (PK) and Sort Key (SK):
- Products:
- PK: PRODUCT#{ID}
- SK: PRODUCT# + attributes (e.g., timestamp, size, color, category)
- Orders:
- PK: ORDER#{ID}
- SK: PRODUCT# + attributes (e.g., timestamp, productId, status)
- Customers:
- PK: CUSTOMER#{ID}
- SK: CUSTOMER# + attributes (e.g., timestamp, location, age)
- Products:
- Attributes:
- Products: productId, productName, description, price, category, timestamp (if applicable)
- Orders: orderId, customerId, productIds (as a list or set), totalPrice, status, timestamp (if applicable)
- Customers: customerName, email, address, and any other relevant details.
Global Secondary Indexes (GSI)
- GSI1:
- PK: ENTITY#PRODUCT, ENTITY#ORDER, ENTITY#CUSTOMER
- SK: other attributes
- This allows querying all products, orders, and customers by ID and additional criteria.
- GSI2:
- PK: CUSTOMER#{customerId}
- SK: ORDER#{orderId}
- This enables querying orders by customer ID.
- GSI3:
- PK: PRODUCT#{productId}
- SK: ORDER#{orderId}
- This allows querying orders by product ID.
With this schema, each order generates multiple entries with the same orderId but different productIds as part of the sort key or GSI sort key, facilitating efficient order and product queries. It’s important to note that all GSIs are optional and should be tailored to specific use cases and access patterns.
Customer X places an order, creating entries in DynamoDB and enabling specific accessing patterns/queries. Admin X creates a product, generating an entry and relevant accessing patterns/queries.
Conclusion
By adopting DynamoDB's single-table design, we can simplify our data management, enhance performance, and reduce costs. This approach provides a flexible and scalable solution for organizing your data, whether for a small application or a large-scale system.
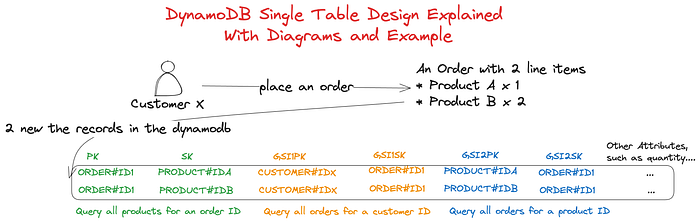
Chapter 2: Implementing Single-Table Design
In this section, we will explore practical implementations of DynamoDB's single-table design.
The first video provides insights into how to simplify your code and enhance performance using DynamoDB's table design strategies.
The second video offers a real-life case study on getting started with DynamoDB's single-table design, illustrating its practical applications and benefits.