Unlocking the Power of PySpark with Google Colab in 4 Minutes
Written on
Getting Acquainted with PySpark and Google Colab
If you have a passion for big data, PySpark is an essential tool for you. This open-source processing engine is capable of handling data on both single-node machines and clusters. In this guide, we'll embark on the journey of executing your first Python program using Spark and explore the basics of Spark SQL and DataFrames.
“Tell me and I forget, teach me and I may remember, involve me and I learn.”
— Benjamin Franklin
I invite you to engage with the content and write your code alongside me step-by-step.
Understanding the Distinction: Apache Spark vs. PySpark
Apache Spark is primarily developed in Scala, while PySpark serves as a Python API for Spark. Within PySpark, the SQL library enables SQL-like analysis on structured or semi-structured data, allowing us to perform SQL queries seamlessly.
In this tutorial, we will delve deeper into PySpark and its SQL functionalities.
Prerequisites:
Loading CSV Files with PySpark
Loading a CSV file is straightforward with the spark.read function. This function returns a DataFrame. The parameters include:
- File path: Specify the path to your CSV file.
- Header: Set to True if your file has a header, otherwise False.
If inferSchema is set to False, all data will be treated as strings. To see the advantages of inferSchema=True, print the data types with both settings and compare the outcomes.
titanic_df = spark.read.csv("/content/train.csv", header=True, inferSchema=True)
display(titanic_df) # Display the DataFrame
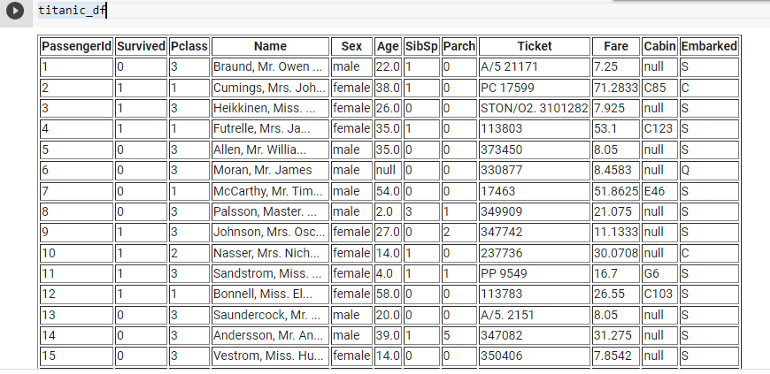
Limiting Records Displayed
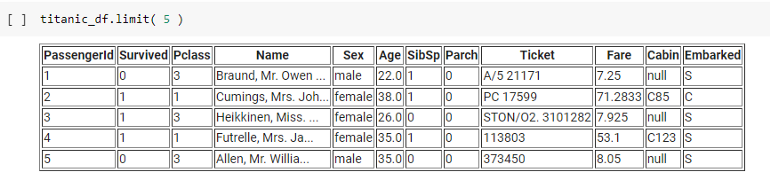
You can control how many records are shown by utilizing the limit function:
titanic_df.limit(5) # Display the first 5 records
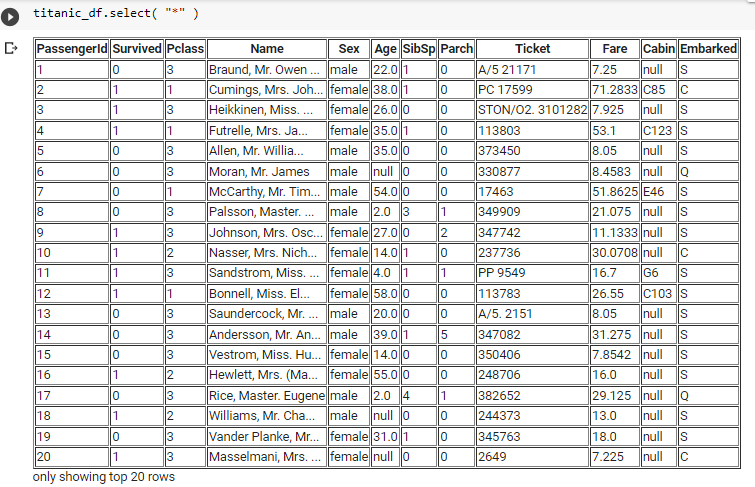
Exploring Data with PySpark SQL
PySpark offers built-in SQL functions. To view data as a table, use the SQL select function. Selecting all columns can be done with:
titanic_df.select("*")
To display specific columns, include their names in the select function:
titanic_df.select("PassengerId", "Survived").limit(5)

Filtering Data for Analysis
To analyze data effectively, we must filter it. For instance, to find the number of females over 25 years old, use the following command:
titanic_df.where((titanic_df.Age > 25) & (titanic_df.Sex == "female")).limit(5)
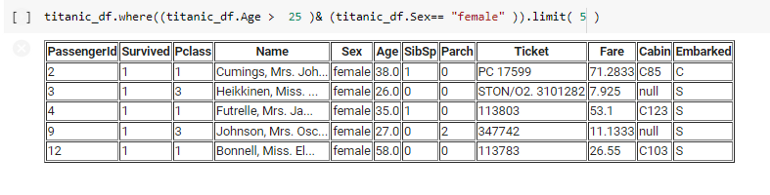
Aggregating Data
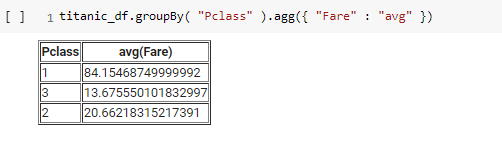
For aggregation and grouping by certain columns such as Pclass, use the following command to calculate the average fare:
titanic_df.groupBy("Pclass").agg({"Fare": "avg"})
Creating Temporary Views
To create a temporary view and load the DataFrame, use:
titanic_df.createOrReplaceTempView("Titanic")
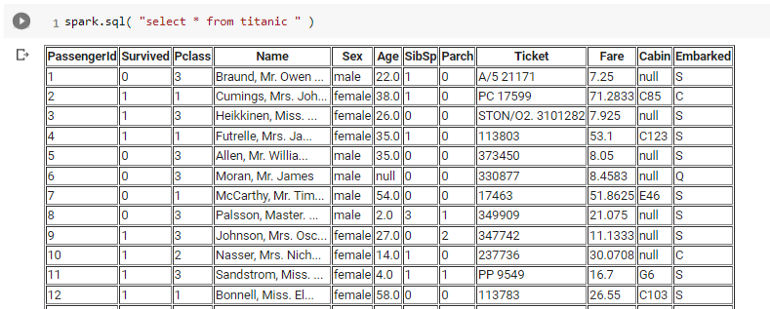
A notable feature of Spark is the ability to use SQL syntax:
spark.sql("SELECT * FROM Titanic")
I hope you found this guide both enjoyable and informative. Feel free to share your thoughts, feedback, or questions. Don’t forget to connect with me on LinkedIn or follow my Medium account for updates!
Did you enjoy this article? Hit the Follow button! You might also like:
Nano Degree Program for Data Engineering — Is It Worth It?
I enrolled in a Nano degree program for data engineering and will share my insights in this article.
Airflow from Zero: Installing Airflow in Docker
A comprehensive tutorial on setting up Airflow using Docker.
How to install PySpark on Google Colab - YouTube
This video demonstrates the step-by-step process of installing PySpark in Google Colab, making it easier for you to get started.
How to Setup PySpark on Google Colab and Jupyter Notebooks in 2 Minutes - YouTube
This quick tutorial shows how to set up PySpark on both Google Colab and Jupyter Notebooks efficiently.