The Future of AI: Meta's Self-Rewarding Language Models
Written on
The Emergence of Self-Rewarding Language Models
Meta, the organization behind platforms such as Facebook, WhatsApp, and Ray-Ban's Meta glasses, has unveiled a groundbreaking advancement in artificial intelligence: Self-Rewarding Language Models. Their latest findings indicate that the LLaMa-2 70B, which has been fine-tuned, outperforms models like Claude 2, Gemini Pro, and GPT-4 0613, despite being significantly smaller in scale.
However, the real significance lies not just in performance metrics; these models hint at a potential pathway to developing the first superhuman language models, even if this trajectory suggests a gradual loss of complete human oversight over advanced AI systems. But what are the implications of this shift? Is it beneficial or detrimental?
To delve deeper into these questions, I draw insights from my weekly newsletter, TheTechOasis, where I discuss the fast-paced developments in AI and encourage readers to stay informed and proactive about the future.
Subscribe to stay ahead in the evolving AI landscape:
Subscribe | TheTechOasis
The newsletter to stay ahead of the curve in AI
thetechoasis.beehiiv.com
The Evolution of Alignment Techniques
In the realm of advanced models like ChatGPT and Claude, human involvement remains paramount. Alignment serves as the essential component, as detailed in a previous issue of my newsletter. The final stages of training these sophisticated language models include human preference training. Essentially, we aim to enhance model utility while minimizing harmful outputs by guiding them to respond as a human expert would.
Constructing a comprehensive dataset of human preferences is a labor-intensive process, wherein various responses to given prompts are evaluated by experts, determining which responses are superior.

This approach demands considerable expert input. Once this dataset is available, two main pathways can be pursued:
- Reinforcement Learning from Human Feedback (RLHF): This method necessitates a reward model of comparable quality to the model being trained. It employs a policy optimization process, guiding the model to maximize the reward based on its responses.
- Direct Preference Optimization (DPO): In contrast, DPO allows the model to optimize without a separate reward model, simplifying the process and reducing costs while still achieving comparable or superior results to RLHF.
Despite its novelty, DPO has already been recognized as a significant advancement.
The SuperAlignment Challenge
While both RLHF and DPO hold promise, they are still limited by human involvement. The dependency on the human preferences dataset implies that these models can only reach the quality established by their human creators. Thus, how can we ensure alignment for future superhuman models that rely on human input?
OpenAI has posited that humans might be capable of aligning superior models, suggesting a paradigm where we can guide models without diminishing their capabilities. However, researchers have concluded that a different strategy is necessary to ensure future superhuman models remain in check. This could potentially be accomplished through Self-Rewarding Models, which represent Meta’s proposition for reducing human input in the alignment process.
The Self-Improvement Framework
Meta proposes an innovative approach where DPO is employed while allowing models to establish their own rewards. If this method proves effective at scale, it represents a revolutionary shift in model training.
Returning to the earlier methods, RLHF incurs high costs and requires a reward model, whereas DPO eliminates the need for a reward model but still mandates human-defined behavior boundaries. In both cases, rewards remain static, based on the quality of the reward model.
Meta's iterative framework begins with the current model (Mt) autonomously generating responses and scoring them, effectively creating its own preference dataset. This dataset is then used with the DPO approach to produce a new aligned model (Mt+1). The cycle continues, leading to further iterations (Mt+2, Mt+3, etc.).
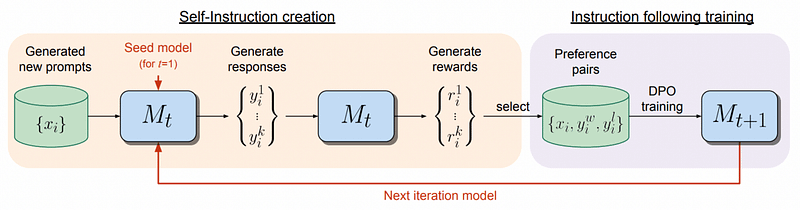
In essence, the model not only becomes better aligned with each iteration but also enhances its ability to evaluate responses, explaining why each new iteration surpasses the previous one.
In layman's terms, where traditional alignment methods necessitate human involvement to create preference datasets, this new approach allows the model to assume both roles—aligner and aligned. The results have been striking: within just three iterations, the refined LLaMa model matched the top competitors, showcasing a self-improving mechanism that shows no signs of plateauing.
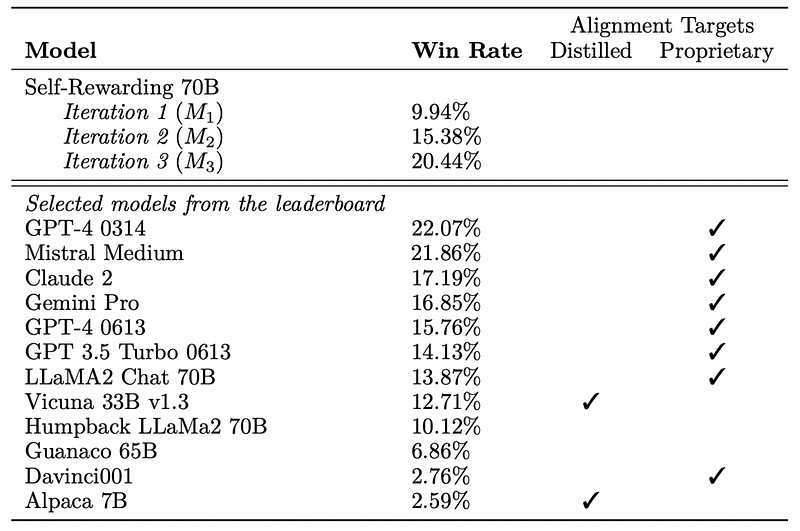
This represents a pivotal moment, as we have not seen a self-improving language model that can operate independently of human oversight. The implications are vast, particularly considering the achievements of self-improving systems like AlphaGo, which triumphed in the game of Go by competing against itself.
The Potential Risks of Removing Human Oversight
The reality is that human involvement has been a bottleneck in the development of superhuman models. However, the prospect of completely removing human influence from training processes warrants careful consideration.
Currently, we struggle to articulate how LLMs ‘think’, yet we still maintain some control over them. By allowing models to autonomously determine optimization strategies, we risk losing that control. The potential for these models to operate unpredictably is a valid concern.
Conversely, this shift could unlock new realms of possibilities and breakthroughs beyond our current understanding, which could be unattainable without superhuman models. Thus, the critical question remains: where do we draw the line?
The Rise of a New Alignment Method
In the video titled "Self-Rewarding Language Models by Meta AI - Path to Open-Source AGI?", the speakers discuss the implications and future potential of Meta's self-rewarding models in advancing artificial intelligence.
Chapter 2: Exploring Further Implications
In the second video, "Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge," the discussion centers around how these models may redefine alignment and self-improvement in AI systems.